








Getting Started
“Attendance” - an unavoidable part of any Cult class!
The QR based attendance is prone to fraud as QR codes can easily be shared with others. Facial recognition based attendance solves this problem and it also serves as a delighting feature for customers.
Facial Attendance is a 2 part process, namely facial registration & facial verification, a combination of which helps us to uniquely identify a person’s face and mark their attendance.
Cult Facial Attendance App
Initial Setup requires a Cult Manager to log in to the app and configure the city and center appropriately
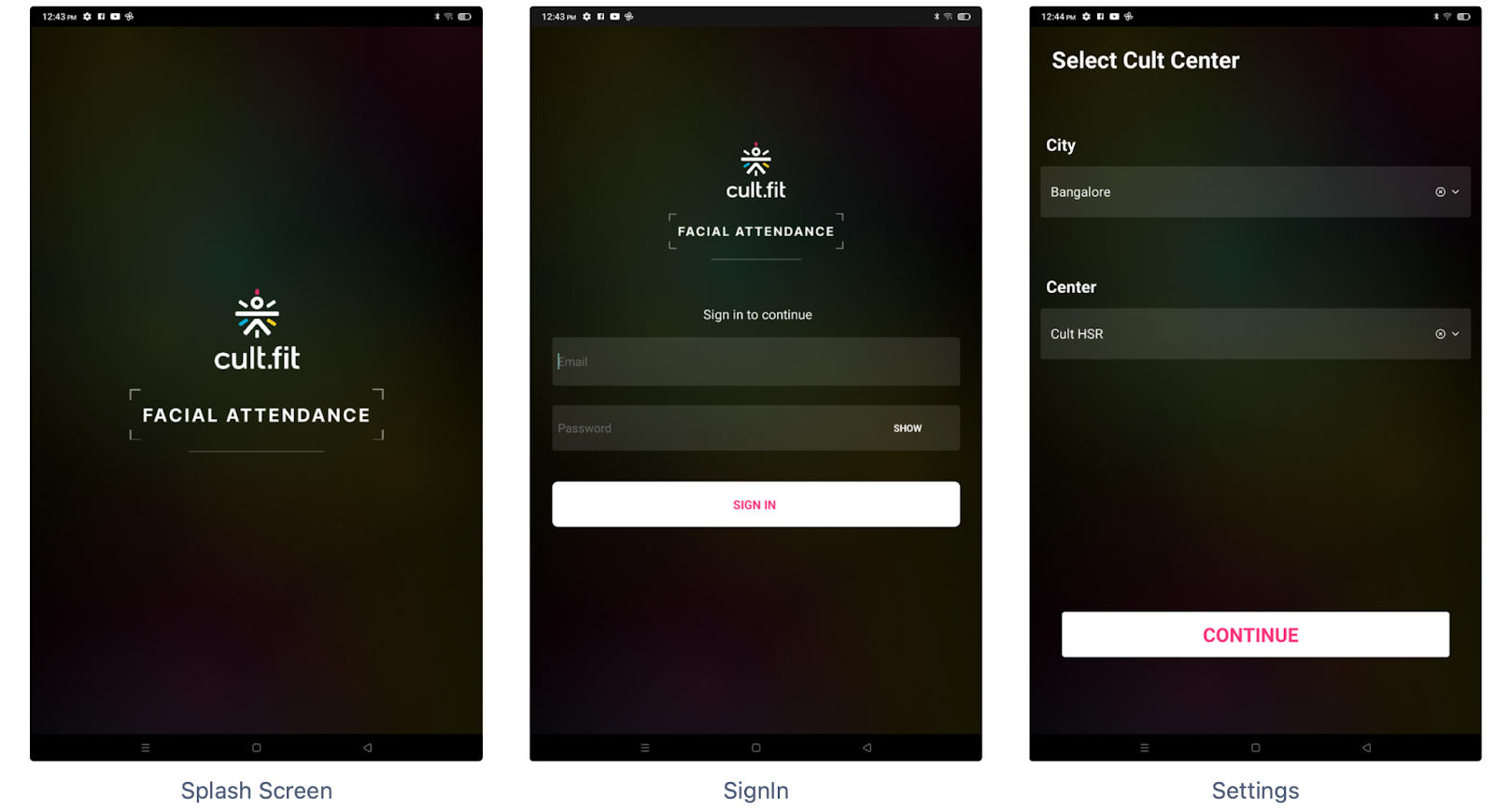
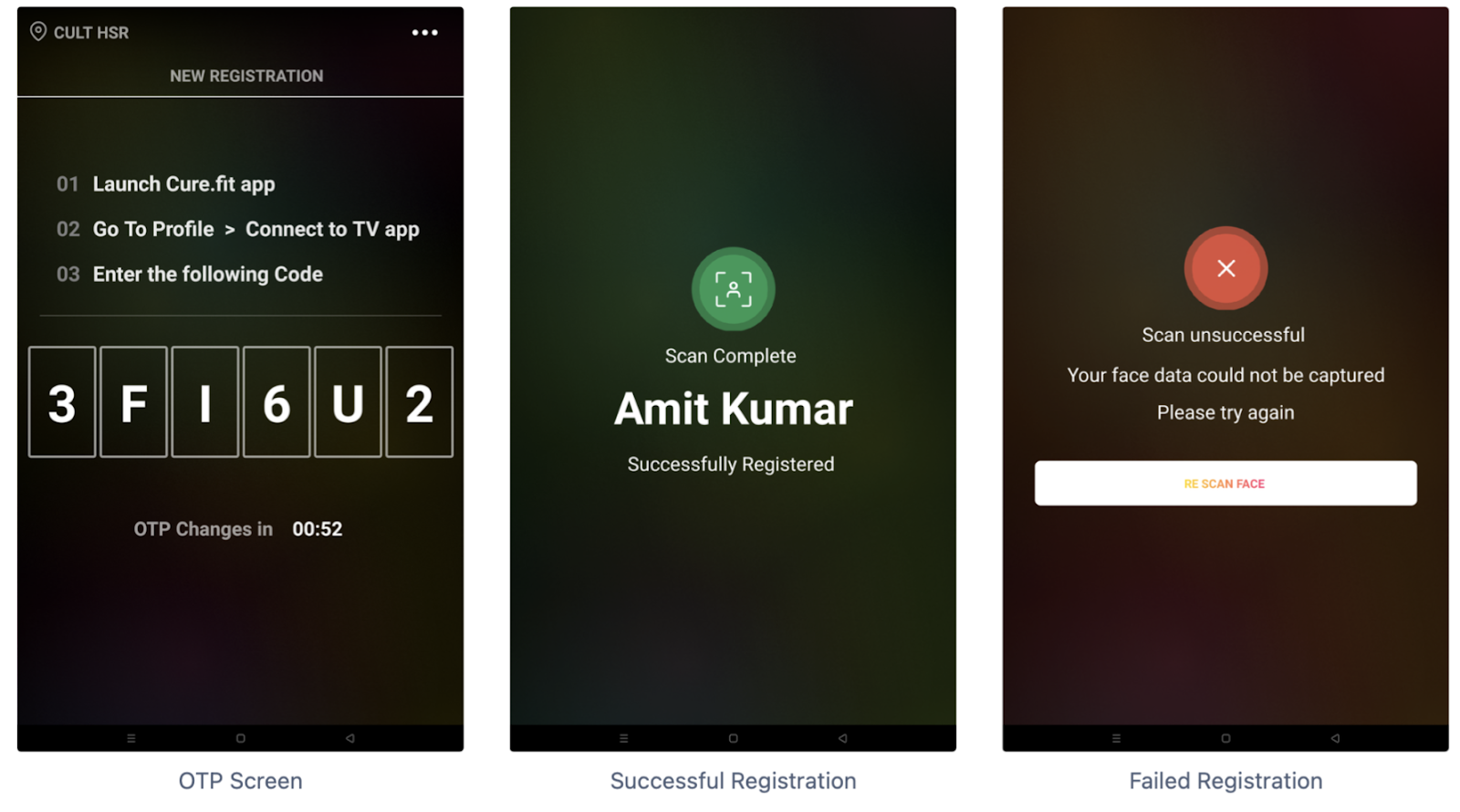
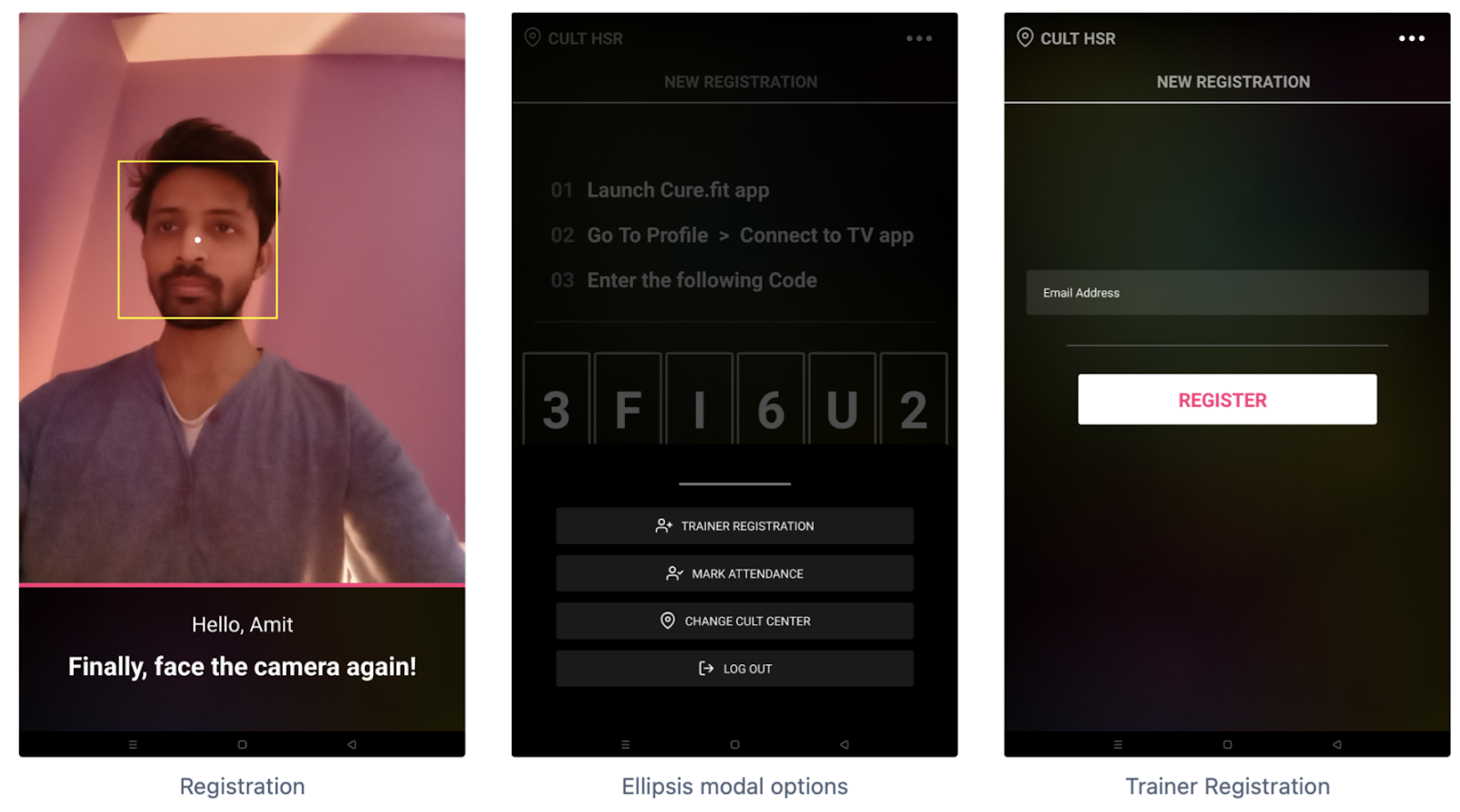
Facial Registration is a process to extract features from images of a person’s face & store those in a database.
The purpose of this flow is to record a certain user’s embeddings and send them to the backend service to be stored in the database. Interval-based cues are present to guide the users to properly register their face vectors by moving their heads around.
Now, registration has two different flows for the two sets of users
- Cult email-address based for Trainers - A trainer would enter their respective cult email-address for the face-scan to begin for registration
- Code based for Customer - A customer would enter the code displayed on the tablet in the “Connect to TV app“ section in their cult.fit app before expiration. On a correct entry, the face-scam for them would begin. We are using the same APIs used by Curefit-TV to generate the code and another API that does long-polling to fetch customer’s details like name, userId etc. who entered the displayed code.
Facial verification is a process to match the face between the detected features with the other existing features in our database either using a classifier or a distance metric algorithm.
A Registered customer would stand in-front of the tablet camera at the center to mark their attendance for booked classes at the cult centers. Their embeddings get recorded and are sent to the service. The service would try to run these embeddings against a classifier for the center if available during that time slot. If there's a hit, an attempt to mark attendance would be made by making a call to cult-api for attendance. A failed response is sent back to the app for any of the cases - face not recognised, booking for the user-id was not found, attempt to mark attendance outside the attendance time-slot bounds.
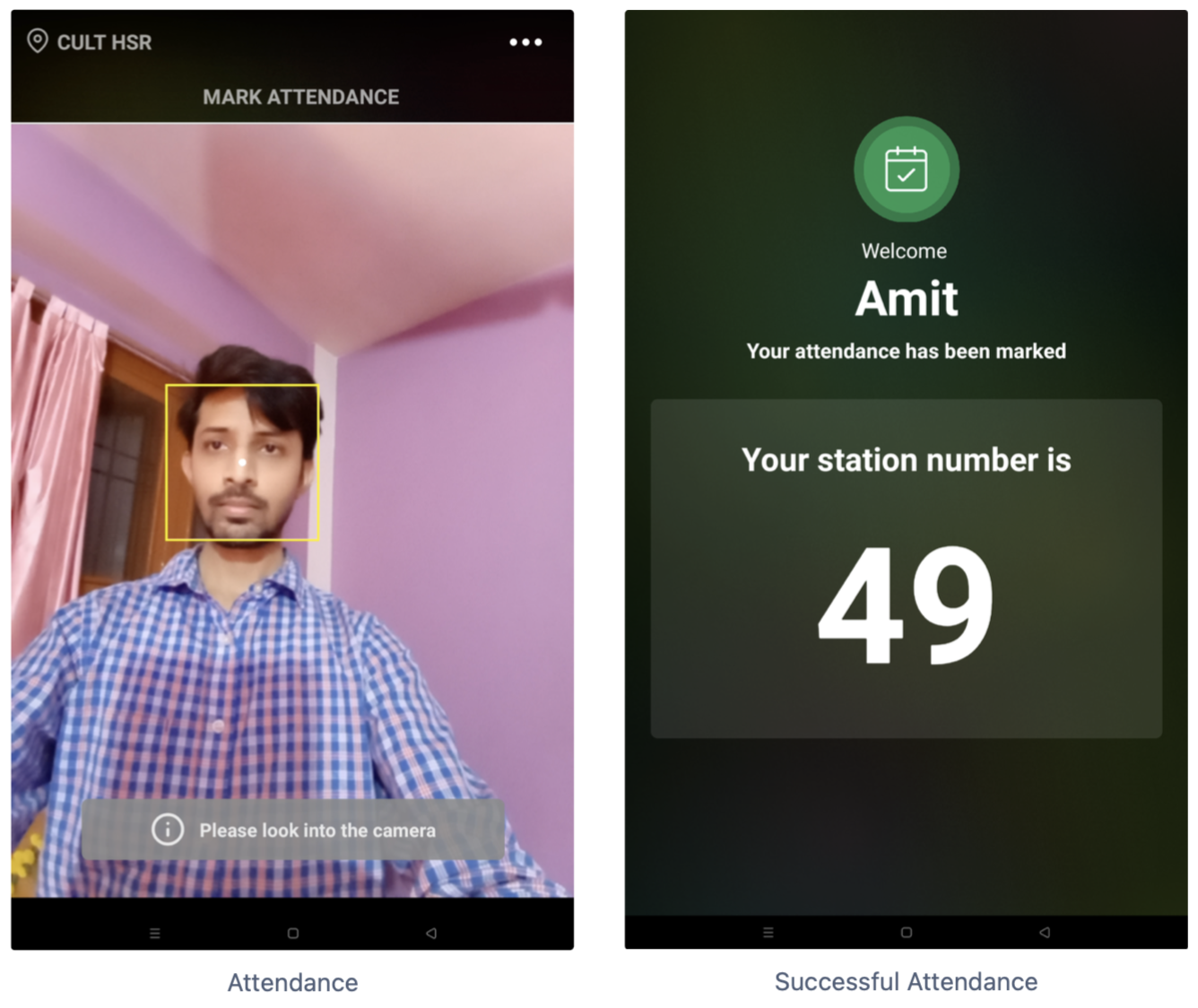
Successful attendance with allotted station number
Implementation
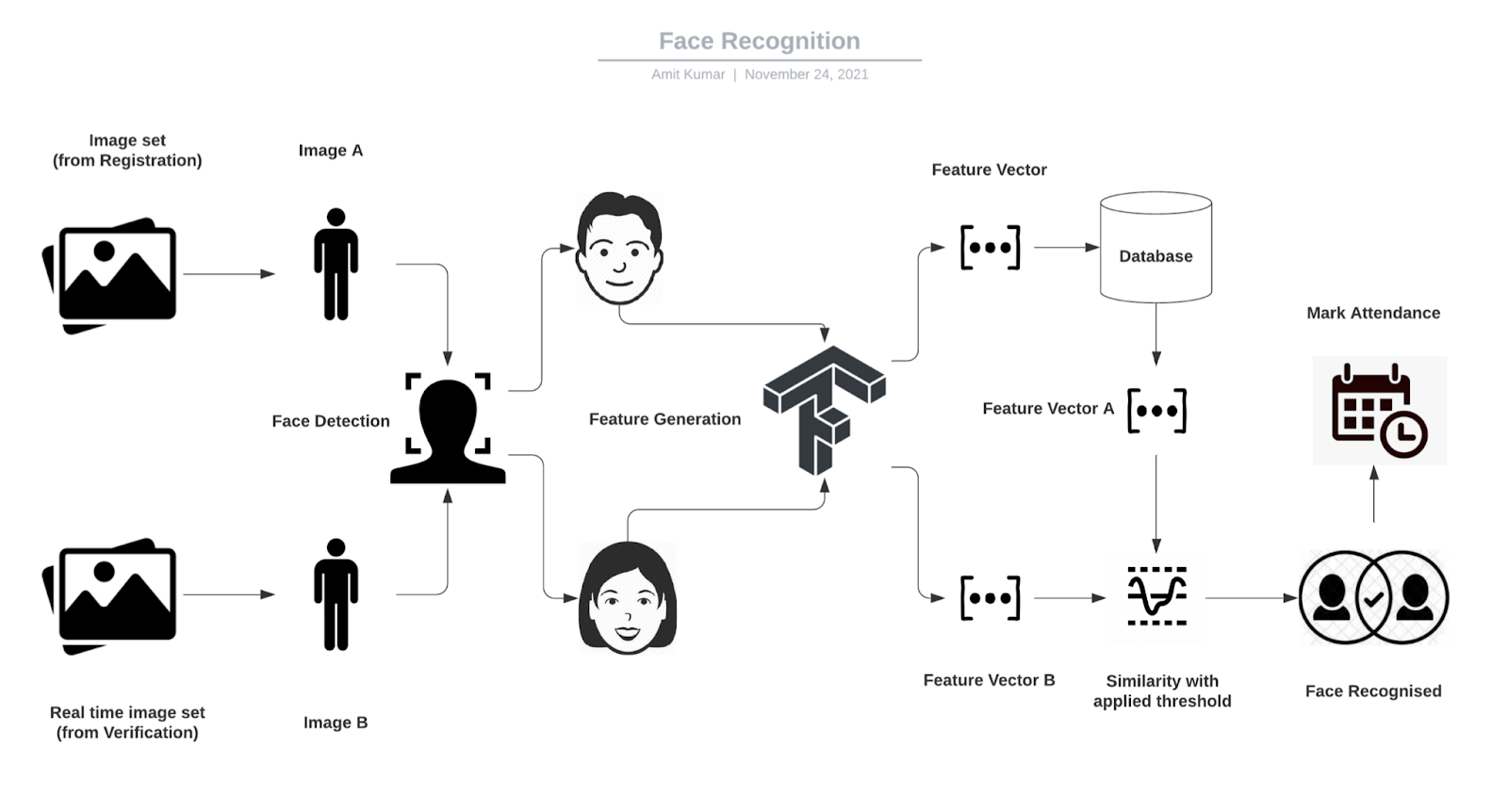
Facial Attendance Architectural Overview
Both registration and verification share some common ground in terms of initial computational steps and have been natively implemented.
1. Capturing frames using Camera2 API
Camera2 has come a long way to customize the interaction with the camera. It has been available since API level 21, and provides in-depth controls for complex use cases but requires you to manage device-specific configurations.
The user is requested to grant access permissions to the phone camera at runtime therefore we initialize a CameraManagerfor system service called CAMERA_SERVICE for interacting with camera devices.
val manager = activity.getSystemService(Context.CAMERA_SERVICE) as CameraManager
try {
if (!mCameraOpenCloseLock.tryAcquire(2500, TimeUnit.MILLISECONDS)) {
throw RuntimeException("Time out waiting to lock camera opening.")
}
if (ActivityCompat.checkSelfPermission(context, Manifest.permission.CAMERA) !=
PackageManager.PERMISSION_GRANTED
) {
ActivityCompat.requestPermissions(activity, arrayOf(Manifest.permission.CAMERA), 0)
return
}
manager.openCamera(mCameraId!!, mStateCallback, mBackgroundHandler)
The main UI thread shouldn’t be overloaded, hence a separate thread is created for running such tasks assigned as mBackgroundHandle.
While mStateCallback serves as a handler for camera state callback asCameraDevice.StateCallback] is called when [CameraDevice] changes its state which acts as a listener indicating when the camera is opened and when it failed to do so.
Finally, define the default camera facing (front or back)
val facing = characteristics.get(CameraCharacteristics.LENS_FACING)
if (facing != null &&
facing != CameraCharacteristics.LENS_FACING_EXTERNAL &&
facing != CameraCharacteristics.LENS_FACING_FRONT)
A callback OnImageAvailableListener was setup for every new image available. The callback fires for every new frame available from ImageReader and it is converted into a bitmap object using BitmapFactory. The bitmap is further preprocessed i.e rotated and converted into an InputImage object for the graphicOverlay which renders the read image on the phone screen.
object : ImageReader.OnImageAvailableListener {
override fun onImageAvailable(reader: ImageReader) {
val image = reader.acquireLatestImage() ?: return
...
}
}
The InputImage object is further fed to the facial recognition models for detection followed by feature generation.
2. Face Detection
To detect a face in a picture and identify key facial features, Firebase ML Kit was used, a tool that tries to simplify bringing machine learning algorithms to mobile devices.
val options = FaceDetectorOptions.Builder()
.setPerformanceMode(FaceDetectorOptions.PERFORMANCE_MODE_FAST)
.setContourMode(FaceDetectorOptions.LANDMARK_MODE_NONE)
.setClassificationMode(FaceDetectorOptions.CLASSIFICATION_MODE_NONE)
.build()
faceDetector = FaceDetection.getClient(options)
The output of detection results in coordinates to the Bounding Box for the face, rotation angles for the face along the Yand Z axes, coordinates to the 68 facial landmarks, and certain feature probabilities.
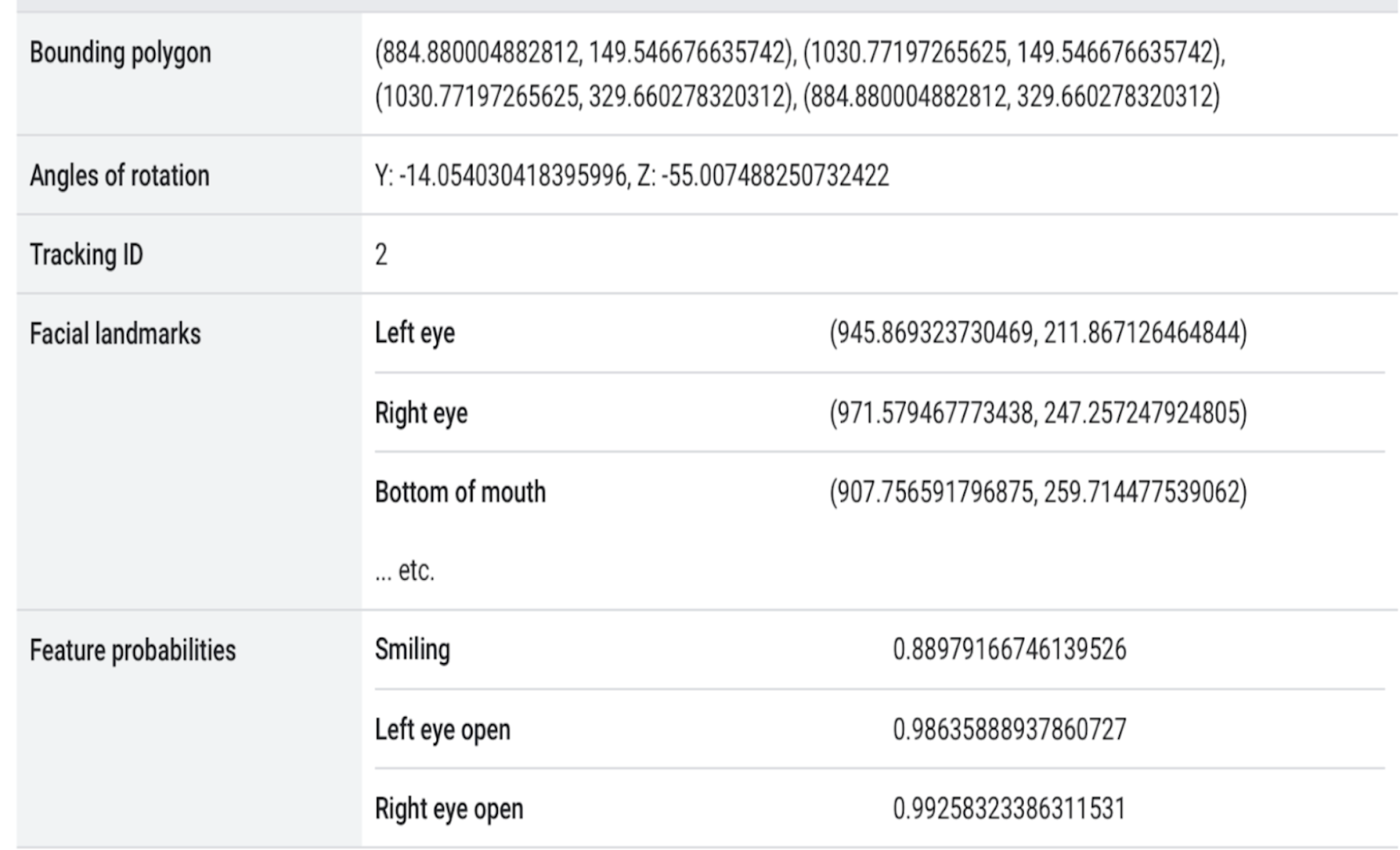
ML-Kit Face Detection
Another callback is setup for the face detector. For every face detected in an image, the image/bitmap is cropped down to the region of interest (ROI) or only the face using the Bounding Box coordinates. The cropped Bitmap is further scaled down for the feature generation (TFLite MobileNet) model to an input size of 112x112.
3. Feature Generation
The feature extraction is applied to generate the feature data or feature vector representation. The process of training a convolutional neural network to output face embeddings requires a lot of data and computer power. But once the network has been trained, it can generate measurements for any face, even ones it has never seen before.
What do we mean by features?
Feature extraction is the basic and most important initializing step for face recognition. It extracts the biological components of your face. These biological components are the features of your face that differ from person to person. Various methods extract various combinations of features, commonly known as nodal points.
Nodal points are endpoints that in this case are able to measure certain variables of a person's face, including the width or length of the nose, space between eyes and depth of eye sockets, and even the contour of the cheekbones.
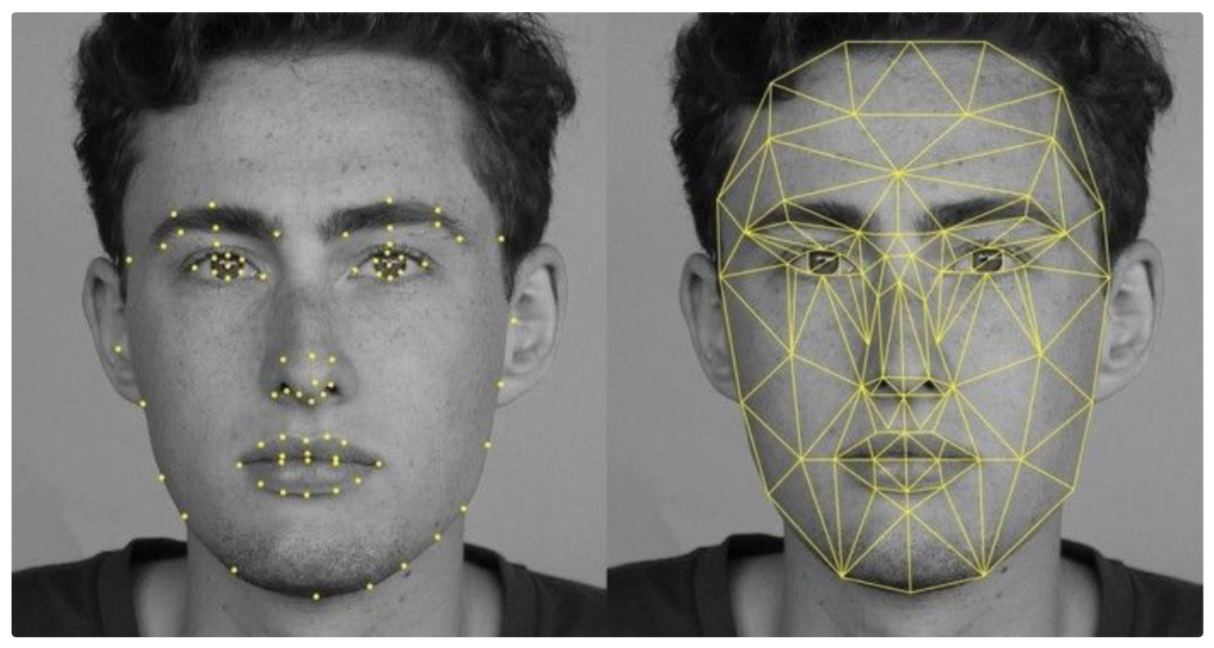
192 Face Embeddings
Credits to this excelent MobileFaceNet implementation in TensorFlow, from sirius-ai which serves as the source of inspiration for our model
The resulting mobileNet tflite file is very light-weight, only 5.2 MB, really good for a mobile application use cases
The main idea is that the deep neural network (DNN) takes as input a face and gives as output a D dimensional (D = 192) normalized vector (of floats), also known as embeddings.

Feature generation from scaled image
4. Thresholding
At the time of classification, the predictions which have a Euclidean distance between recorded and registered embeddings greater than a defined threshold value are ignored, falling under misclassification to handle false positives and false negatives cases.
To reach this exact value, another classifier is modeled to find the right fit. The modeling was performed on a combination of 3 datasets
- FaceScrub + Labeled faces in the wild - 13233 images, ~6K people - http://vintage.winklerbros.net/facescrub.html
https://paperswithcode.com/datasets?q=face+recog&v=lst&o=match
- Yale multi illumination dataset - 9206 images, 28 people
https://www.face-rec.org/databases/
- Cult.fit internal dataset - 300 images, 6 people
For every image in the merged dataset, face embeddings were generated using the same tflite model. The similarity between embeddings for each image was computed against every other image (one-to-one) which results in 2 classes, Selfwhen an image (embedding) was compared with another image (embedding) of the same class and Other when an image (embedding) was compared with another image (embedding) of a different class.
The problem statement here is to find the right split on the Euclidean distance which could tell whether images pertained to the same person or different.
To solve this, a C4.5(regular) Decision Tree algorithm (classifier) was applied to find the best split(threshold) for the distance to differentiate between the 2 classes.
5. Optimizing app size
The pretrained mobileNet model used for feature generation has a size of approximately 5MB. Rather than embedding the tflite model into the APK that increased the size by 5MB, the file is stored in an AWS S3 bucket and downloaded at the time of model initialization. A check is initially made if the model is already presented in the internal storage else it downloads it.
Model downloading from S3 cannot be performed on the same UI thread (main) therefore, a separate thread is created to carry out tflite model initialization to handle the network operation when needed.
Permissions for Internal storage need to be added to AndroidManifest
<uses-permission android:name="android.permission.READ_INTERNAL_STORAGE" />
<uses-permission android:name="android.permission.WRITE_INTERNAL_STORAGE" />
6. Pass embeddings from Native to JS
Once the vectors are generated they are passed to the appropriate JS module through a React Native Bridge using ReactContext bound to an event on the native side. onRecognitionResult serves as a callback for the event at the react end.
val reactContext = context as ReactContext
reactContext
.getJSModule(RCTEventEmitter::class.java)
.receiveEvent(id, "onRecognitionResult", event)
Backend Service
The backend service stores and manages the facial embeddings of the users (customers, trainers, etc.) onboarded to the facial attendance service. NodeJS, MongoDB, and Redis serve as the building blocks for this service.
A KNN classifier optimized using a KDTree implementation.
Once N such embeddings for a face have been recorded, they are passed down to the Classifier. The KDTree helps to optimize search space for KNN thereby, improving its complexity roughly from linear to logarithmic.
Euclidean distance is used to measure the similarity between the normalized embeddings i.e between the ones that were recorded against the ones that were fetched for the registered users from the database.
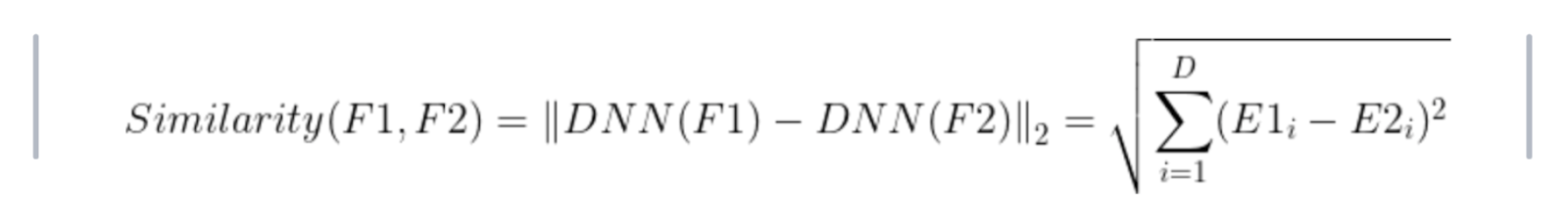
Similarity between faces can be computed as the euclidean distance between its embeddings
Metrics
Number of Trainer onboarded
120
Number of CMs onboarded
6
Number of Customers onboarded
9
Accuracy
99.7%
Mean time to Register
15s
Mean time taken to mark Attendance
2.25s
Centers Pilot is Live in
Cult HSR 19th Main
Device being at the center
realme Pad 3 GB RAM 32 GB ROM 10.4 inch
Demo
Attendance - https://drive.google.com/file/d/13xDt18UrHsBbHUbeUiM_XEDwMRLVgKoD/view?usp=sharing
Registration -
https://drive.google.com/file/d/14bZVsTya1a_rf4CZIXx_7Un-6gtJPr1H/view?usp=sharing
Future work
From our experiments earlier, we discovered that the current feature generation model is somewhat biased towards light complexion people. Therefore we plan to train a feature generation model with mobileNet backbone on a different dataset.
More from
Engineering
category

